- 歡迎使用超級蜘蛛查,網站外鏈優化,收藏快捷鍵 CTRL + D
今日头条搜索spider介绍
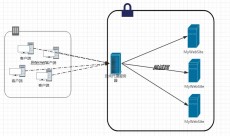
頭條搜索的爬蟲UA為“Bytespider”首寫字母為大寫。每個獨立的搜索引擎都有自己的網頁抓取程序爬蟲(Spider)。爬蟲順著網頁中的超鏈接,從這個網站爬到另一個網站,通過超鏈接分析連續訪問抓取更多網頁。被抓取的網頁被稱之為網頁快照!

一、頭條搜索UA介紹
頭條搜索的爬蟲UA為“Bytespider”首寫字母為大寫。
例如:
例如:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML,like Gecko)Chrome/41.0.6633.1032 Mobile Safari/537.36;
Bytespider;bytespider@bytedance.com
二、頭條搜索ip字段介紹
頭條搜索的ip字段總共涉及6個,具體字段如下:
110.249.201.0/24
110.249.202.0/24
111.225.148.0/24
111.225.149.0/24
220.243.135.0/24
220.243.136.0/24
三、基本流程
1.抓取網頁。
每個獨立的搜索引擎都有自己的網頁抓取程序爬蟲(Spider)。爬蟲順著網頁中的超鏈接,從這個網站爬到另一個網站,通過超鏈接分析連續訪問抓取更多網頁。被抓取的網頁被稱之為網頁快照。由于互聯網中超鏈接的應用很普遍,理論上,從一定范圍的網頁出發,就能搜集到絕大多數的網頁。
2.處理網頁。
搜索引擎抓到網頁后,還要做大量的預處理工作,才能提供檢索服務。其中,最重要的就是提取關鍵詞,建立索引庫和索引。其他還包括去除重復網頁、分詞(中文)、判斷網頁類型、分析超鏈接、計算網頁的重要度/豐富度等。
3.提供檢索服務。
用戶輸入關鍵詞進行檢索,搜索引擎從索引數據庫中找到匹配該關鍵詞的網頁;為了用戶便于判斷,除了網頁標題和URL外,還會提供一段來自網頁的摘要以及其他信息。
四、問題反饋
1.如果您的網站發現有頭條spider的UA“Bytespider”抓取存在抓取量過大,導致您的網站出現緩慢、掛掉等問題,您可以通過“抓取頻次”功能,對網站進行設置抓取要求,我們會在1天內時間內生效。
2.關于spider有其他問題,可以向zhanzhang@bytedance.com提交反饋,我們會在及時處理。