- 歡迎使用超級蜘蛛查,網(wǎng)站外鏈優(yōu)化,收藏快捷鍵 CTRL + D
搜索引擎知多少?
“搜索”在這個數(shù)據(jù)信息冗雜的時代里,充當著人們信息的篩選器,人們通過使用搜索功能,可以獲得自己想要的內容,屏蔽掉無用的信息。對于商家來說,理論上,搜索功能在一定程度上可以增加長尾信息的曝光度。
但是,總所周知,搜索引擎的排序規(guī)則實際上飽含水分,競價排名的規(guī)則下,長尾信息的曝光可能就打水漂了。
所以,無論是C端還是B端的產品經理,深諳搜索引擎規(guī)則,并學會利用好搜索引擎都非常重要。

一、 初識搜索引擎
提及搜索引擎,大家腦海中就會浮現(xiàn)起國內的百度和國外的Google,我們想要查找什么資料,直接在搜索框中輸入關鍵字,點擊搜索按鈕,之后就會展現(xiàn)搜索結果。
其實這只是搜索引擎的一部分,我們使用微博搜索某個明星,使用淘寶搜索商品,使用豆瓣搜索一本書,都是搜索引擎。這些搜索引擎因為太常用,我們反而沒有意識到。
搜索引擎本質上是一種信息獲取方式。
搜索引擎主要經歷了:分類目錄、相關性搜索、高質量搜索、個性化搜索四個階段。
在搜索引擎誕生前,我們使用分類目錄來獲取信息。Yahoo!和國內hao123是分類目錄的代表。當時信息相對較少,通過人工整理,把屬于各個類別的高質量網(wǎng)站羅列出來。
比如:按照財經類、新聞類、體育類、游戲類等項目進行整理,用戶可以通過分類目錄來查找需要的信息。
但一個頁面的展示空間有限,分類目錄也只能收錄少數(shù)的網(wǎng)站,絕大多數(shù)網(wǎng)站都無法被收錄,而那些沒有被收錄的信息,可能正是大家需要的。
有需求,就有商機,搜索引擎順勢而生。
最早的搜索引擎,通過查找用戶輸入的關鍵詞與網(wǎng)頁信息的匹配程度,也就是計算兩者的相關性,展示網(wǎng)頁列表,至于如何計算匹配程度,會在后文講解。
相比分類目錄,這種方式可以收錄大量的網(wǎng)頁,并按照用戶查詢的關鍵詞和網(wǎng)頁內容的匹配程度進行排序。
但這種方式有個巨大的問題:只考慮了相關性,沒有考慮網(wǎng)頁的質量。網(wǎng)頁可以通過大量羅列跟內容無關的關鍵詞,來提高與關鍵詞的相關性。
比如:一家做教育的網(wǎng)站,可能會羅列明星、寵物、新聞甚至色情等高流量詞語,這種“強行蹭流量”的方式,造成的后果就是搜索結果質量并不好。
解決這個問題的是Google,Google假設網(wǎng)頁的鏈接越多,網(wǎng)站質量越高。利用網(wǎng)頁之間的鏈接數(shù)量來確定網(wǎng)頁質量,一個網(wǎng)頁的鏈接數(shù)量越多,說明在網(wǎng)頁在整個互聯(lián)網(wǎng)中質量越高,Google的核心算法,也會在后文講述。
發(fā)展到現(xiàn)在,搜索引擎不僅需要解決相關性和質量的問題,還要更多考慮用戶的真實需求,比如:同樣輸入“蘋果”,年輕人可能想的是手機,另外一些人想到的是水果。這就需要更加復雜的算法和程序了。
二、什么是好的搜索引擎
從分類目錄、相關性搜索、高質量搜索、個性化搜索,我們可以從搜索引擎的發(fā)展階段看出,搜索引擎越來越復雜,用戶體驗也更好了。
那么,如果判斷一個搜索引擎好不好呢?
主要有三個評價標準:
1. 好的搜索引擎要快
速度是用戶對搜索引擎的第一個印象。
當用戶搜索一件商品,幾十秒還沒有搜索到,他可能去干其他事情了,就直接放棄購買了!商用搜索引擎的查詢速度要達到毫秒級,一眨眼的功夫,搜索結果就出來了,用戶體驗就很好。
影響搜索速度的因素有很多,索引是最關鍵的因素之一,關于索引,會在下一節(jié)詳細介紹。
2. 要查的準
當用戶翻了3頁還找不到想要的內容,干脆就不找了。
影響查詢準確率的因素同樣有很多,主要有下面這三個:
搜索引擎本身存儲的信息要全,對于百度等商用搜索引擎,這就要求爬蟲能夠爬取全網(wǎng)內容。
關鍵詞和網(wǎng)頁內容的相關性要高,用戶搜索手機,結果有很多單反相機,就不太好了。
網(wǎng)頁信息質量要高,Google發(fā)明的PageRank算法很巧妙地解決了這個問題。
3. 搜索引擎要具有穩(wěn)定性
這也是用戶對大多數(shù)產品的要求,給用戶一個合理的預期,用戶才能夠信任這款產品,三天兩頭不能用了,體驗就差極了。
搜索引擎是怎么工作的?
那么,搜索引擎到底是如何工作的呢?
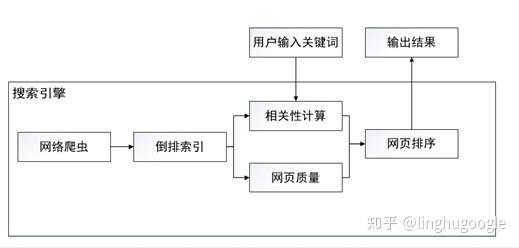
一個最基本的搜索引擎主要分為:信息獲取、信息處理、信息展示三個模塊。
巧婦難為無米之炊,信息獲取是整個系統(tǒng)的基石。對商用搜索引擎而言,要求爬蟲能夠爬取全網(wǎng)內容,關于爬蟲,我們再上一章已經介紹過了,這里就不再贅述。對網(wǎng)站內部搜索引擎而言,也需要把信息匯總起來,比如:電商平臺,就需要把所有的產品信息存儲到一起。
信息處理主要是對原始數(shù)據(jù)清洗,存入數(shù)據(jù)庫,這里最重要的一個環(huán)節(jié)就是構建索引,相當于給每一個內容添加目錄,便于查找。
信息展示指搜索引擎根據(jù)用戶的查詢詞(query)來進行數(shù)據(jù)庫檢索,將結果展示給用戶,主要涉及到用戶查詢內容與網(wǎng)頁內容的相關性分析、網(wǎng)頁質量評價等技術。
雖然搜索引擎具體實現(xiàn)方式有差異,但所有的搜索服務都可以在這三個模塊的基礎上實現(xiàn)。
三、內容索引
搜索引擎為什么這么快?
好的搜索引擎的評價標準之一就是要快,那么搜索引擎是如何實現(xiàn)的呢?
在開始講解之前,我們可以考慮另外一個相似的問題:如何在圖書館找到一本書?
最笨的方法是一個書架、一個書架地找,這會花費大量的時間。
聰明一些的方式是通過索書號,快速找到所在書架,進而找到這本書。
搜索引擎中的索引就相當于圖書館里每本書的索書號,通過索引,可以快速找到需要的信息。
索引到底長啥樣?
以網(wǎng)頁搜索引擎為例:下面這張圖是一個簡單的索引系統(tǒng)(更準確的說法是倒排索引,至于為什么是倒排,這里先賣個小關子,后面會講到)。
左邊是關鍵詞,右邊是這個關鍵詞出現(xiàn)在哪個網(wǎng)頁中,一個關鍵詞可能同時出現(xiàn)在很多網(wǎng)頁中,所以是一對多的關系。
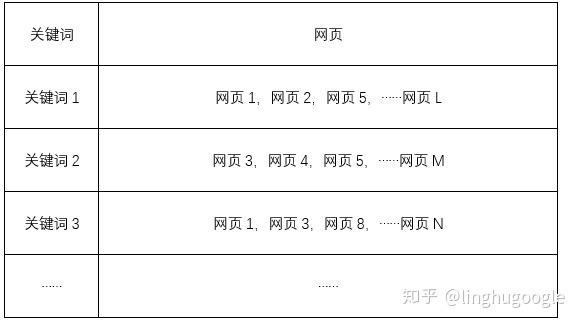
與圖書館索引不同是:一個圖書館再大,藏書畢竟還有有限的,圖書管理員可以手工給每個圖書建立索書號。但搜索引擎存儲的數(shù)據(jù)都是以億計算的,不可能手工建立索引,只能借助一些技術手段。
從上面的表格我們可以看出,構建索引主要有兩個過程:查找關鍵詞,把關鍵詞和網(wǎng)頁對應起來。
關鍵詞
構建索引的前提是提取出關鍵詞,那么給定一個文本(也就是網(wǎng)頁的文字內容),如何獲取里面的關鍵詞呢?
主要有兩步:首先是獲得文本里出現(xiàn)的所有詞語,也叫做分詞,之后再從中篩選一些作為關鍵詞。
第一步,分詞。
如果是一句英文,“Marry had a little lamb”,每個詞都是用空格分開的,里面有“marry”、“had”、“a”’、“l(fā)ittle”、“l(fā)amb”這五個單詞,但中文“瑪麗有一只小綿羊”,因為沒有分隔符(比如:空格)把每個詞語分開,就有些麻煩了。
最容易想到的分詞方法就是查字典,把句子從左到右看一遍(程序員的說法叫做遍歷),每個詞語如果在字典中出現(xiàn)過就標記出來。
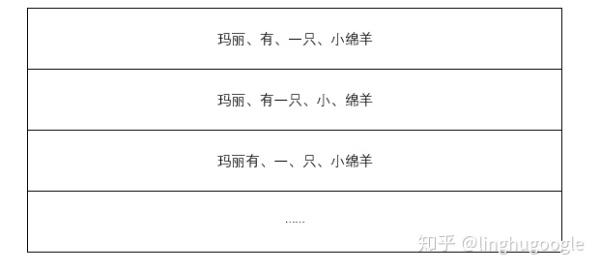
拿“瑪麗有一只小綿羊”舉例,比如:“瑪麗”這個詞在字典中出現(xiàn)過,就把“瑪麗”作為一個詞語,“有”在詞典中出現(xiàn)過,就把“有”作為一個詞語,就這樣一直做下去,最后可以分為“瑪麗、有、一只、小綿羊”。
這種最簡單的方式可以解決一部分問題,但也有很大的問題,比如是“小”“綿羊”還是作為整體的“小綿羊”呢?
程序員使用統(tǒng)計學解決這個問題:
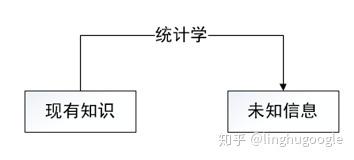
從形式上看,詞是字的組合,兩個字組合在一起可能是一個詞語,也可能不是,如果是詞語的可能性(概率)大一些,我們就傾向于認為它們可以組成詞語。
這就像:天氣預報說明天下雨的概率70%,不下雨的概率30%,我們就傾向于認為明天下雨。“小綿羊”一起出現(xiàn)的概率是70%,分開出現(xiàn)的概率是30%,我們就傾向于認為“小綿羊”是一個詞語。
那么,如何計算相鄰的字組成詞語的概率呢?
我們可以對語料庫中相鄰出現(xiàn)的各個字的組合的次數(shù)進行統(tǒng)計,計算所有的字相鄰出現(xiàn)的頻率,當語料庫足夠大時,出現(xiàn)的頻率越高,對應的概率也就越高。
我們可以計算一個句子中所有組合出現(xiàn)的概率,產生最大的概率組合,就是分詞的結果。
比如:“瑪麗、有、一只、小綿羊”每一個詞語出現(xiàn)的概率就大于“瑪麗、有一、只、小、綿羊”等其他組合出現(xiàn)的概率,那么,我們就認為這個句子就按照“瑪麗、有、一只、小綿羊”劃分。
第二步,獲得關鍵詞。
對所有的文本分詞之后會發(fā)現(xiàn),“的”、“了”、“嗎”、“也許”等沒有很強實際意義的功能詞有很多,相比之下“產品經理”、“搜索引擎”等詞語更加具有實際意義的反而較少,后者更應該作為關鍵詞。
于是,我們使用把所有這些功能詞存起來,作為停用詞(stop word),如果一個詞語出現(xiàn)在停用詞中,就不能作為關鍵詞。于是,我們就從分詞結果中,獲得了關鍵詞。
下面是一個簡單的停用詞表,可能看出,基本都是我們經常使用的、沒有很強實際意義的詞語。
中文分詞是幾乎所有中文自然語言處理(Natural Language Processing)的基礎,所以學術界和產業(yè)界對中文分詞的技術研究已經很深入了,有高質量的商用分詞庫,也有像jieba這樣的開源中文分詞庫,可以免費使用。
通過提取每個網(wǎng)頁的關鍵詞,最終每個網(wǎng)頁和關鍵詞的對應關系如下:
需要注意的是:獲取關鍵詞不僅用在網(wǎng)頁處理,而且也用在輸入搜索框中。當我們搜索一句中文的時候,搜索引擎內部會進行分詞、去掉停用詞,獲得關鍵詞,之后再進行后續(xù)處理。
倒排索引
現(xiàn)在,我們已經建立好了索引,對于每一個網(wǎng)頁,我們找到了出現(xiàn)的所有關鍵詞。
當用戶查詢時,我們從頭到尾,對每一篇文件掃描一遍,看哪個網(wǎng)頁出現(xiàn)了用戶查詢的關鍵詞,就把這個文件作為搜索結果。
但問題是:動輒上億的網(wǎng)頁數(shù)量,從頭到尾掃描一次就要花好長時間,根本無法滿足正常的需求,更別說快速響應了。
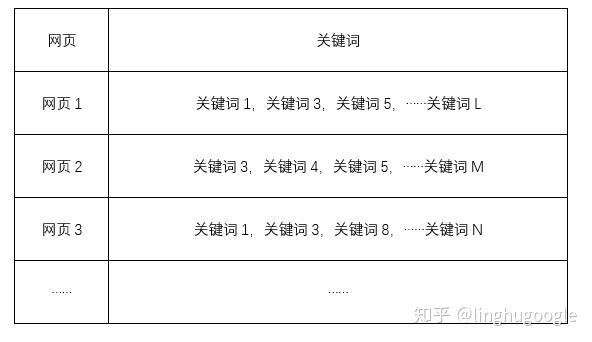
那我們能不能把關鍵詞放前面,網(wǎng)頁放后面?
這樣,當我們檢索的關鍵詞的時候,不需要遍歷整個系統(tǒng),只用查找對應的幾個關鍵詞,就可以找到需要的網(wǎng)頁了!
對計算機而言,直接尋找關鍵詞所在位置的信息,所需的時間非常短,完全可以滿足搜索的需要。
比如:用戶搜索“關鍵詞1”,那么搜索引擎只需要找到“關鍵詞1”,就可以會直接找到“網(wǎng)頁1,網(wǎng)頁2,網(wǎng)頁5,……網(wǎng)頁L”。
用戶搜索“關鍵詞1+關鍵詞2”,那么搜索引擎需要找到“網(wǎng)頁1,網(wǎng)頁2,網(wǎng)頁5,……網(wǎng)頁L”,“網(wǎng)頁3,網(wǎng)頁4,網(wǎng)頁5,……網(wǎng)頁M”,找到同時出現(xiàn)的“網(wǎng)頁3、網(wǎng)頁5,……”。這樣就大大加快了呈現(xiàn)排名的速度。

把“文件-關鍵詞”這種結構顛倒一下,“關鍵詞-文件”,就是倒排索引名字的由來。
更進一步,倒排索引中不僅僅記錄了包含網(wǎng)頁的ID,還會記錄關鍵詞出現(xiàn)的頻率(term frequency)、每個關鍵詞對應的文檔頻率(inverse document frequency),以及關鍵詞出現(xiàn)在文件中的位置等信息,這些信息可以直接用在搜索結果排序上。
四、搜索結果排序
至此,我們通過爬蟲實現(xiàn)了信息獲取、通過倒排索引實現(xiàn)了信息處理,接下來就是如何把這些信息展示給用戶,其中最關鍵的是如何排序。
對電商而言,用戶可以選擇按照銷量、信用、價格甚至綜合排序,當然, 排序中也會穿插一些推廣。
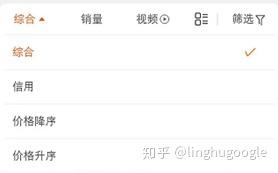
對通用的搜索引擎而言,比如:百度,沒有銷量、評分這些選項,主要根據(jù)網(wǎng)頁與搜索關鍵詞的相關性、網(wǎng)頁質量等排序。
TF-IDF模型
如何確定網(wǎng)頁與關鍵詞的到底有多大的相關性?
如果一個網(wǎng)頁中關鍵詞的出現(xiàn)很多次的話,我們通常會認為這個網(wǎng)頁與搜索的關鍵詞更匹配,搜索結果應該更靠前。
我們用詞頻(Term Frequency, TF)表示關鍵詞在一篇文章中出現(xiàn)的頻率,代表網(wǎng)頁和關鍵詞的匹配程度。
比如:我們在百度等搜索引擎上搜索“產品經理的工作”,關鍵詞為“產品經理”,“工作”,“的”作為停用詞,不出現(xiàn)在關鍵詞中。
在某一個網(wǎng)頁上,總共有1000個詞,其中“產品經理”出現(xiàn)了5次,“工作”出現(xiàn)了10次,“產品經理”的詞頻就是0.005,“工作”的詞頻就是0.01,兩者相加,0.015就是這個網(wǎng)頁和“產品經理的工作”的詞頻。
這里有一個問題,相較“產品經理”,“工作” 這個詞用的更多,在所有的網(wǎng)頁中出現(xiàn)的概率也很高。搜索者可能希望查找產品經理相關的信息,按照TF排序,一些出現(xiàn)很多次“工作”這個關鍵字的網(wǎng)站,就可能排在前面,比如:《程序員的工作》、《老板的工作》等等,逆文本頻率 (Inverse Document Frequency,IDF)應運而生。
文件頻率(Document Frequency)可以理解為關鍵詞在所有網(wǎng)頁中出現(xiàn)的頻率,如果一個關鍵詞在很多網(wǎng)頁中都出現(xiàn)過,那么它的文件頻率就很高。反之亦然,比如:“工作”的DF就高于“產品經理”。
文件頻率越高,這個詞就越通用,有效的信息就越少,重要性應該更低。于是,我們把文件頻率取個倒數(shù),就形成了逆文本頻率。
二八定律在這里同樣適用,20%的常用詞占用了80%的篇幅,大多數(shù)關鍵詞出現(xiàn)的頻率都很低,這就造成了文件頻率很小,而逆文本頻率很大,不便于處理。于是我們取對數(shù),便于計算(當然,這里也有其他數(shù)學和信息論上的考慮)。
把詞頻(TF)、逆文檔頻率 (IDF)相乘,就是大名鼎鼎的TF-IDF模型了。
一個關鍵詞在一個網(wǎng)頁中出現(xiàn)的頻率越高,這個關鍵詞越重要,排名越靠前;在所有網(wǎng)頁中出現(xiàn)的頻率越高,這個關鍵詞告訴我們的信息越少,排名應該更靠后。
TF-IDF模型幫助我們解決了關鍵詞與網(wǎng)頁相關性的計算,僅僅使用TF-IDF模型,也可以搭建出效果不錯的搜索引擎。
當然,商用搜索引擎在TF-IDF的基礎上,進行的一定的改進,比如:出現(xiàn)在文章開頭和結尾的關鍵詞更加重要,會根據(jù)詞出現(xiàn)的位置調整相關度。但還是基于TF-IDF模型的調整。
大名鼎鼎的PageRank
搜索結果排序,僅僅考慮相關性,搜索的結果并不是很好。總有某些網(wǎng)頁來回地倒騰某些關鍵詞,使自己的搜索排名靠前(當然,部分原因也來自某些搜索引擎更加喜歡推薦自家的東西,這個就不屬于技術問題了)。
引入網(wǎng)頁質量,可以解決這個問題。排序的時候,不僅僅考慮相關性,還要考慮網(wǎng)頁質量的高低,把質量高的網(wǎng)頁放在前面,質量低的放在后面。
那么,如何判斷網(wǎng)頁質量呢?
解決這個問題的是兩位Google的創(chuàng)始人。搜索引擎誕生之初,還是美國斯坦福大學研究生的佩奇 (Larry Page) 和布林 (Sergey Brin) 開始了對網(wǎng)頁排序問題的研究。
他們的借鑒了學術界評判學術論文重要性的通用方法,看論文的引用次數(shù),引用的次數(shù)越高,論文的質量也就越高。他們想到網(wǎng)頁的重要性也可以根據(jù)這種方法來評價。
佩奇和布林使用PageRank值表示每個網(wǎng)頁的質量,其核心思想其實非常簡單,只有兩條:
如果一個網(wǎng)頁有越多的鏈接指向它,說明這個網(wǎng)頁質量越高,PageRank值越高,排名應該越靠前;
排名靠前的網(wǎng)頁應該有更大的表決權,當一個網(wǎng)頁被排名靠前的網(wǎng)頁鏈接時,PageRank值也越高,排名也更靠前。
我們做一個類比:
有一個程序員,如果公司的人都夸他編程技術高,那么我們認為他編程技術高;
如果他被公司的CTO賞識,我們基本可以確定他的編程水平確實牛。
比如:下面這張圖(專業(yè)術語叫做拓撲圖),每一個節(jié)點都是一個網(wǎng)頁,每條線都是兩個網(wǎng)站之間的鏈接。
鏈接越多,說明網(wǎng)站質量越高,相應的PageRank值就越高。
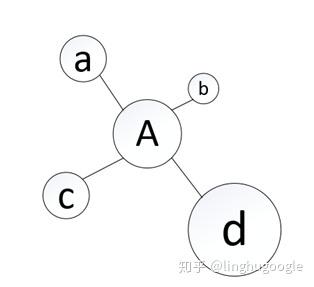
這里有個問題:“當一個網(wǎng)頁被排名靠前的網(wǎng)頁鏈接時,其排名也應靠前”,一個網(wǎng)頁的排名的過程需要用到排名的結果,這就變成了“先有雞還是先有蛋”的問題了。
Google的兩位創(chuàng)始人用數(shù)學解決了這個問題:
最開始的時候,假設搜索的網(wǎng)頁具有相同的PageRank值;根據(jù)初始值,開始第一輪的計算,按照鏈接數(shù)量和每個網(wǎng)頁的PageRank值重新計算每一個網(wǎng)頁的PageRank值;按照上一輪的結果,按照鏈接數(shù)量和每個網(wǎng)頁的PageRank值重新計算每一個網(wǎng)頁的PageRank值……
這樣計算下去,直至每個網(wǎng)頁的PageRank值基本穩(wěn)定。
你可能會好奇,這樣要計算多少次?
佩奇在論文中指出:對網(wǎng)絡中的3.22億個鏈接進行遞歸計算,發(fā)現(xiàn)進行52次計算后可獲得收斂穩(wěn)定的PageRank值。
當然,PageRank實際運行起來比這個更加復雜,上億個網(wǎng)頁的PageRank值計算量非常大,一個服務器根本無法完成,需要多臺服務器實現(xiàn)分布式計算了。為此,Google甚至開發(fā)出了并行計算工具MapReduce來實現(xiàn)PageRank的計算!
除了巨大的計算量,PageRank同樣要面對作弊的問題。
開頭我們談到TF-DIF的弊端的時候講到:總有某些網(wǎng)頁來回地倒騰某些關鍵詞,使自己的搜索排名靠前。
同樣的,針對PageRank,也總有些網(wǎng)頁來回地倒騰鏈接,使自己的搜索排名靠前。這就需要更多的算法,來識別這些“作弊”行為,我們在搜索引擎反作弊一節(jié)再來細講。
其他排序方式
至此,使用TF-IDF計算網(wǎng)頁與搜索內容的相關性,使用PageRank計算網(wǎng)頁質量,可以很好地實現(xiàn)網(wǎng)頁排序,一個基本的搜索引擎就搭建完成了。
商用搜索引擎在此基礎上,還衍生了出其他的排名方式。
競價排名:
比較著名的是百度推出的競價排名(其實最開始做競價排名的不是百度,但百度做得太“成功”,也至于大家都認為是百度發(fā)明了競價排名),競價排名按照按網(wǎng)站出價高低決定排名先后。
這種排名方式最大的優(yōu)點是:可以幫助搜索引擎公司盈利。
最大的弊端是:無法保證出價高的網(wǎng)頁的質量高,在醫(yī)療等特殊領域,有時甚至相反。
隨著用戶數(shù)據(jù)的積累,關鍵詞和對應用戶點擊網(wǎng)頁的行為數(shù)據(jù)也被搜索引擎記錄下來了,搜索引擎可以根據(jù)用戶的操作,不斷改進自己的引擎。
時至今日,商用搜索引擎的底層技術都差不了太多,用戶數(shù)據(jù)記錄成為了競爭的關鍵因素,這也是百度得以在國內的搜索引擎市場獨占鰲頭的重要原因——用戶越多,搜索越準確,搜索越準確,用戶越多!
站內搜索:
百度、Google等通用搜索引擎要做很多工作,相比之下,站內搜索就簡單很多——數(shù)據(jù)量少、也基本都是整理過的結構化數(shù)據(jù),比如:豆瓣讀書,搜索的時候直接檢索自己的數(shù)據(jù)庫就可以了。
雖然站內搜索的技術與通用搜索引擎有很多不一樣的地方,但構建索引、相關性計算、質量計算、排序等流程基本一致。對于站內搜索的需求,同樣存在開源的解決方案。
業(yè)界兩個最流行的開源搜索引擎——Solr和ElasticSearch,它們運行速度快、效果好、可靠性高、可擴展,最關鍵的是免費,足以滿足一般的商業(yè)需求。
對大多數(shù)公司而言,直接使用開源搜索引擎就可以了,不用重新造輪子,甚至,這些開源的解決方案比自己從頭搭建的還更加穩(wěn)定可靠。
五、 SEO與搜索引擎反作弊
搜索引擎結果排名影響流量,流量影響利潤,有利潤的地方就有“商機”,SEO就是針對搜索引擎排名的“商機”。
SEO(Search Engine Optimization)中文為搜索引擎優(yōu)化——即利用搜索引擎的規(guī)則提高網(wǎng)站在搜索結果的排名。
SEO優(yōu)化通常有兩種方式:一種是網(wǎng)站內部優(yōu)化,一種是外部優(yōu)化。
內部優(yōu)化主要是優(yōu)化網(wǎng)頁內容,比如:提高關鍵詞的數(shù)量,優(yōu)化網(wǎng)頁內部標簽等。更有甚者,一些網(wǎng)頁會使用非常小的字重復關鍵詞,或者使用跟背景相同的顏色重復一些高流量詞語,以實現(xiàn)較高的排名。
外部優(yōu)化主要優(yōu)化鏈接,比如:添加友情鏈接、論壇、貼吧、知道、百科等,這就產生了買賣鏈接的生意。
可以看出:SEO的優(yōu)化基本針對的就是TF-IDF和PageRank的排序方式,“投其所好”提高自己的排名。
搜索引擎反作弊
從用戶的角度講:高質量的、相關的信息才是真正需要的。
一些網(wǎng)頁憑借SEO優(yōu)化獲得較高排名,本身可能質量不高、相關性也比較弱,這對那些老老實實提供優(yōu)質內容的網(wǎng)站也是不公平的。
長此以往,可能就會產生“劣幣驅逐良幣”,搜索引擎搜索到的優(yōu)質內容不斷減少。
從這個角度看,SEO就是針對搜索引擎的作弊,搜索引擎公司也不希望這樣的事情發(fā)生——搜索不到需要的信息,用戶也許直接就跑了!
Google誕生初期,就一直面對作弊與反作弊的問題。
在2001年,敏感的站主和SEO優(yōu)化者發(fā)現(xiàn):有些網(wǎng)站的Google排名一夜之間就一落千里,有的網(wǎng)站排名則大幅上升,這個現(xiàn)象幾乎是每月一次。
后來,人們才知道,Google定期地更新它的反作弊算法,提高搜索質量,這給人的感覺就像跳舞一樣,因此被SEO稱為Google Dance。
那么,Google是如何反作弊的呢?
雖然各種作弊行為的方式各不相同,但目標一致,都是為了獲得更高的排名,大體上還是有一定規(guī)律的。根據(jù)這些規(guī)律,搜索引擎常用的反作弊方式有兩類:根據(jù)作弊特征的主動出擊,建立“黑白名單”的被動防御。
首先,搜索引擎會根據(jù)作弊網(wǎng)站的特征主動出擊。
就像我們總是能從人群中一眼看到長得最特殊的人一樣,一個出現(xiàn)大量重復關鍵詞網(wǎng)頁、一個出現(xiàn)大量鏈接的網(wǎng)頁和一個普通的網(wǎng)頁,在搜索引擎看來是很不一樣的。
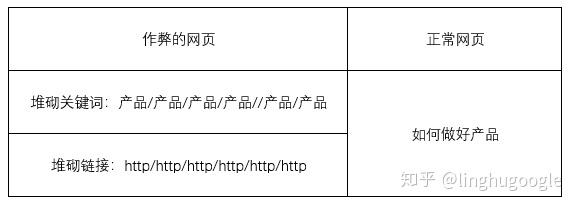
通過計算網(wǎng)頁的關鍵詞數(shù)量特征、鏈接數(shù)量特征,可以很快發(fā)現(xiàn)那些“出格”的網(wǎng)站,搜索引擎就可以憑此調整排名。(前文所述的Google Dance就是根據(jù)作弊網(wǎng)站鏈接異常實現(xiàn)反作弊的。)
其次,搜索引擎也會建立“黑白名單”,作為防御手段。
搜索引擎會根據(jù)網(wǎng)站內容的質量、品牌、權威程度等信息建立一個白名單,比如:政府網(wǎng)站、一些大公司網(wǎng)站就在白名單中,這些網(wǎng)站的質量較高,排名也靠前,白名單鏈接的網(wǎng)站質量一般也會較高。
與之對應的是黑名單,主要包括那些作弊嚴重的網(wǎng)站——比如:堆疊關鍵詞、買賣鏈接的網(wǎng)站。如果同一個網(wǎng)站鏈向了多個黑名單中的網(wǎng)站,就可以把其認定為作弊的網(wǎng)站,降低排名。
貓鼠游戲
《貓鼠游戲》夢工廠出品的一部電影,根據(jù)真實經歷改編,講述了FBI探員與擅長偽造文件的罪犯之間進行一場場貓抓老鼠的故事。在搜索引擎中,也同樣存在這樣的貓鼠游戲。
為什么電商網(wǎng)站商品名稱這么長?
為什么會好評返現(xiàn)?差評有償刪除?
為什么有些評價很高的賓館/餐廳,實際卻臟亂差?
為什么電影評價網(wǎng)站經常會因為刷好評/差評進入輿論中心?
為什么微博等社交媒體會有令人咂舌的閱讀、點贊和轉發(fā)數(shù)量?
網(wǎng)站和商品本身的相關性和質量很難客觀量化,根據(jù)關鍵詞、銷量、評價、點擊、閱讀量等較為客觀的指標生成排序結果,甚至決定是否進入熱搜榜、熱銷榜,仍然是當前搜索引擎的工作原理。
搜索引擎面對這些行為,也不斷進化出新的應對策略。
面對刷單行為,平臺經歷了睜一只眼閉一只眼的無可奈何,到物流追蹤、下單用戶身份判斷的演變,刷單成本也隨之急劇上升,刷單行為雖然沒有被杜絕,但也大幅下降。
面對閱讀量、點擊造假等方式,社交媒體也經歷著從聽之任之到屏蔽刷排名的轉變,中間雖然有收入的降低、用戶活躍度下降、大V流失的風險,但也終究要踏上這一步。
相關文章推薦
- 百度百科上線“超級名片”,成了網(wǎng)紅們的營銷新玩法
- SEO推廣就是搜索引擎優(yōu)化和推廣
- SEO搜索引擎優(yōu)化詞庫匹配算法
- 解讀百度SEO搜索優(yōu)質內容指南
- 搜索流量與推薦流量的區(qū)別聯(lián)系
- 百度APP移動端搜索悄然下線點贊按鈕
- 百度取消百度快照,內容“時效性”進一步加強
- 百度正在暴力截流SEO,企業(yè)老板應該怎么做
- 解答百度搜索引擎優(yōu)化的十五個問題
- 搜狗網(wǎng)站收錄頁面要訣,搜狗快速收錄方法
- SEO搜索引擎優(yōu)化:搜索引擎的工作流程的三個階段
- 分析網(wǎng)站快照停滯的9個原因及解決辦法
- 搜索引擎營銷推廣,分享百度引流的一些技巧
- 為什么網(wǎng)站首頁老不被百度收錄,百度近期收錄異常情況大全
- 簡要說明七大搜索引擎站長平臺入口