- 歡迎使用超級蜘蛛查,網站外鏈優化,收藏快捷鍵 CTRL + D
SEO搜索流量公式解读
SEO是一個多邊的生態,“用戶”、“你的站點”、“競品站點”、“搜索引擎”,這4個點隨便一個發生變化,都有可能導致自身站點的SEO流量波動。其實還應該把像新浪、知乎這種“流氓站點”也算進來,但是“流氓站點”拿到不同行業流量的占比差不多是恒定的,所以也不那么重要。

任何行業,判斷任何手段是夠有效的前提,是“有反饋”,而反饋時間越長,這越會影響判斷的準確性。
比如網站流量漲了,有可能不代表SEO搞的好,可能是因為某個競品網站的流量掉了。比如有些高競爭、存在巨頭網站的行業,一個處于第二梯隊的網站流量變化,大部分取決于巨頭網站的流量變化,它掉,你才有可能漲,它不掉,你就沒機會漲,所以,除非行業整體搜索量變大,否則只能放棄行業流量競爭,尋找行業弱相關的流量來做。
然而在搞SEO的過程中,很容易把大部分目光集中在“自身網站”,而忽視了“用戶”、“競品網站”、“搜索引擎”的變化。之前流傳很廣的SEO公式,“整體收錄量×整體排名×整體點擊率×整體搜索量”這個,放到現在感覺十分尷尬。
比如其中幾個子因素:
整體收錄率 = 搜索引擎抓取量 × 頁面質量
排名 = 頁面排名 × 網站權重增益
“頁面質量”怎么定義?什么頁面才能叫頁面質量好的?權重增益又怎么算?
如果能夠得到有效“反饋”的前提,是能夠對結果性指標及其影響因素做出明確且及時的數據量化。而能夠量化,就意味著不能夠使用諸如“頁面質量”、“權重增益”這類含糊其辭的名詞,應該全部換成“XX率”、“XX量”、“XX占比”之類可進行數據計算的明確指標。
基于此,SEO學堂對這個公式做了如下修改:
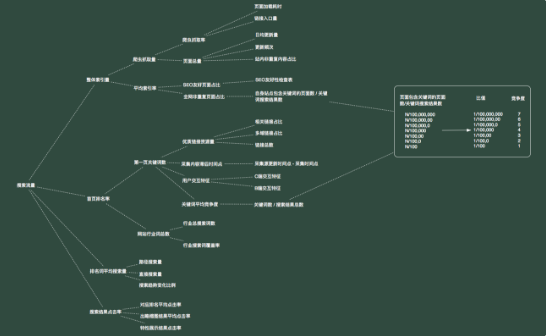
全網非重復頁面占比這是反應競爭度的一個指標,公式為:
全網非重復頁面占比 = 自身站點包含關鍵詞的頁面數 / 關鍵詞搜索結果總數
比方說我拉出1180個詞,標題中完整包含這1180個詞的頁面有3400個,而這1180個詞在百度搜索結果數的總量為1341722539
則:
3466 / 1341722539 = 0.0000025 = 2.5/1000000 = 1/400000
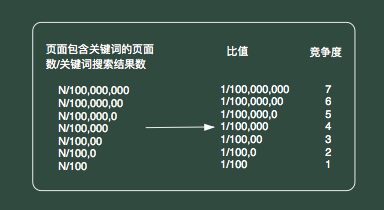
對標一下,競爭度為4到5之間,約4.4左右,這個競爭度,差不多有10%的網頁能夠進入倒排。
采集內容滯后時間點
識別采集網頁最粗暴的特征,就是看網頁上線的時間唄,搜索爬蟲抓到A網頁,隔了2天,抓到B網頁,B網頁正文與A網頁正文幾乎一致,假設兩個權值一樣,哪個留下來的概率大?
所以,如果網站有較大比例內容是采集的,則需要努力縮短采集頁面與源頁面的上線時間間隔。比方說,A網頁12:20發出來的,我12:25就抓過來,12:30就上線了,這種接近于實時同步采集。這種采集,能夠能夠一定比例提升采集內容被收錄的概率。
所以定時采集的站為啥容易掛呢?這個應該是一個比較重要的因素。
真實用戶使用特征
現在一些網站,無論SEO怎么搞,什么上詞、做聚合頁、搞鏈接結構,反正死活上不去,所以感覺高競爭行業的站點,用之前傳統手段搞SEO可能已經行不通了。人無我有的階段,拼的是流量,人有我優的階段,拼的是留存,靠的是產品體驗。所以搜索引擎機器學習到現在,會不會根據有真實用戶使用、體驗好的網頁上的共同特征,來參考其他網頁?比方說我看到阿里巴巴SEO專利有一條關于流量分發的情況,可以理解為,電商網站一個產品詞的SEO搜索頁面。
電商網站有B端和C端用戶,如果一個電商網站有大量真實用戶在使用,那么在網頁產品設計上,必然要考慮給B端用戶分發的流量要盡可能公平。
有大量真實用戶使用的電商網站,會兼顧流量分發,同一個B端用戶發布的商品,在列表中只能出現一次,不能出現多次,也就是列表中出現的商品,全是由不同的B端發布的。
這也就意味著,如果一個電商網站,它產品詞的SEO搜索列表頁,在列表中出現同一個B端用戶發布的多條商品,則這個列表規則意味著對其他B端用戶的不公平。而一個真實用戶量少,或者純靠廣告賺錢的網站,在網頁設計過程中,是不考慮流量分發這一點的。
路徑搜索量
用戶在搜索框,輸入一個關鍵詞,在點擊“百度一下”,這個流量是直接搜索流量。接著上步,跳轉到搜索結果頁,看到下拉框推薦的詞是符合自己需求的,點擊這個詞,這個流量是路徑搜索流量。用戶搜索行為變化越多樣的行業,路徑搜索流量占比越高,比如娛樂行業,每天都有新的熱點出來,圍繞這個熱點,又有很多的衍生詞。
個別幾個行業,通過路徑搜索產生的流量,能夠接近總搜索流量的50%。
相反的,用戶搜索變化緩慢的行業,如招聘,直接搜索詞和路徑搜索詞的重合率有90%,也就是說路徑搜索量在招聘領域,沒多少流量空間。